
티스토리 뷰
4. 가로세로 1cm 프로세서 칩
장치들의 과거 모습과 발전된 모습 비교
하드 드라이브나 SD 카드 패키지는 몇년 전과 똑같이 생겼지만 용량은 훨씬 크고 가격은 더 저렴하다.
컴퓨터 부품이 올라가 있는 회로 기판에서는 요즘에는 부품의 수가 더 적다.
컴퓨터의 전자 회로의 기본 소자
1) 논리 게이트
논리게이트는 레고의 블럭, 리액트의 컴포넌트, 프레임워크의 모듈처럼 일정한 형태로 정형화하여 사용한다. 이렇게 하면, 일일이 논산을 구현하는 시간을 줄일 뿐만아니라, 직관적 사고의 깊이를 얕게 만들어 더 복잡한 연산을 구현할 수 있게 만든다.
한 개나 두 개의 입력 값을 바탕으로 단일 출력 값을 계산해 낸다.
또한 전압이나 전류 같은 입력 신호를 이용하여 전압이나 전류인 출력 신호를 제어한다.
이러한 게이트가 필요한 만큼 적절한 방식으로 연결되면 어떤 종류의 계산도 수행할 수 있다.
웹사이트에서 논리회로가 산술 연산과 여타 계산을 수행하는 방법을 그래픽 애니메이션으로 보여준다.논리게이트는 집적회로상에서 만들어진다.
한때는 논리 게이트가 개별 부품으로 만들어지기도 했다.
2) 트랜지스터
회로를 제어하는 스위치 역할을 할 수 있고 신호를 증폭시킬 수도 있다.
회로 소자에서 가장 핵심적인 부분
스위치(전압의 제어를 받아 전류를 켜거나 끄는 장치) 역할을 한다.

3) 집적회로
트랜지스터를 사용하면 AND 같은 간단한 함수의 회로를 만들 때도 부품이 너무 많이 필요하다.
집적회로를 사용하면 복잡한 시스템도 트랜지스터 하나를 만드는 정도의 비용으로 만들 수 있다.
집적회로는 모양 때문에 칩이라고도 불린다.

모든 소자와 배선이 단일 평면(얇은 실리콘 판) 위에 들어가 있는데, 이는 개별 부품과 재래식 전선이 없는 회로를 만들기 위해 일련의 복잡한 광학적, 화학적 공정을 거쳐 제조된 것이다.
따라서 집적회로는 개별 부품으로 만들어진 회로보다 훨씬 작고 견고하다.
칩은 지름이 약 12인치(30cm)인 원형 웨이퍼 상에서 한꺼번에 제조된다.
붸이퍼는 잘려서 각 칩으로 나뉘고 , 칩은 하나씩 패키징된다.
일반적인 칩은 시스템의 나머지 부분과 칩을 연결해 주는 수십에서 수백 개의 핀이 있는 더 큰 패키지에 장착된다 .
실제 프로세서는 패키지에 들어가 있는 집적회로 중앙에 있고 , 가로세로 길이가 각각 1cm 정도다
집적회로가 실리콘(규소) 기반으로 만들어진다는 점에 착안해서 집적회로 사업이 처음으로 시작된 캘리포니아 샌프란시스코 남부 지역에 실리콘 밸리Silicon Valley라는 별명이 붙었다 .
이제 실리콘밸리는 그 지역에 있는 모든 첨단 기술 회사를 일컫는 약칭이며 , 뉴욕에 있는 실리콘앨리Silicon Alley나 영국 케임브리지에 있는 실리콘펜Silicon Fen 같은 수십 곳의 추종지역을 탄생시켰다.
집적회로가 디지털 전자 장치의 핵심 요소이기는 하지만, 다른 기술도 함께 사용된다.
디스크에는 자기 저장 기술 , CD와 DVD에는 레이저 , 네트워킹에는 광섬유가 사용된다.
이들 모두가 지난 50-60년 동안 크기 , 용량 , 비용 면에서 극적으로 개선됐다.
5. 50년 넘게 유지된 무어의 법칙
고든 무어는 매우 적은 데이터 포인트를 기반으로 추정하면서 , _기술이 향상됨에 따라 일정한 크기의 집적회로에 들어갈 수 있는 트랜지스터의 수가 매년 대략 두 배가 된다_고 관측했다. 나중에 그는 이 비율을 2년마다 두 배로 수정했고,어떤 이들은 18개월마다 두 배로 잡았다 .
트랜지스터의 수는 컴퓨팅 성능을 간접적으로 나타내는 지표이므로 위 내용은 적어도 2년마다 컴퓨팅성능이 두 배로 증가한다는 것을 의미했다.
무어의 법칙Moore's Law이라고 부르는 기하급수적인 증가 양상은 거의 60년 동안 계속 진행됐고 , 이제 집적회로에는 1965년에 비해 100만 배가 훨씬 넘는 트랜지스터가 들어 있다 .
하지만 이제 일부 회로에는 개별 원자가 단 몇 개만 들어갈 수 있는 수준에 이르렀는데 , 이 수준은 제어하기에는 크기가 너무 작다 .
프로세서 속도는 예전만큼 빨리 증가하지는 않으며 , 더 이상 2년마다
두 배가 되지는 않는다. 한 가지 이유는 칩이 너무 빨라져 열을 너무 많이 발생시키기 때문이다. 하지만 메모리 용량은 여전히 증가하고 있다.
한편, 프로세서는 칩 하나에 프로세서 코어를 두 개 이상 배치함으로써 더 많은 트랜지스터를 활용할 수 있고 , 컴퓨터 시스템에는 흔히 프로세서 칩이 여러 개 들어간다 . 즉 , *개별 코어의 실행 속도가 빨라진다기보다는 장착 가능한 코어의 개수가 늘면서 성능이 향상된다고 볼 수 있다. *
참고자료
16. 슈퍼컴퓨터부터 사물 인터넷까지
1) 논리적 구조
- 컴퓨터들은 모두 논리적 구조, 즉 무엇을 계산할 수 있는지에 대해서는 공통된 속성을 가지고 있으며, 비슷한 아키텍처를 갖추고 있지만, 가격, 소모 전력, 크기, 속도 등에서 서로 다른 트레이드오프를 보인다.
2) 사물 인터넷
- 휴대전화와 태블릿 PC도 일종의 컴퓨터로, 운영체제를 실행하며 풍부한 컴퓨팅 환경을 제공한다.
- 우리 주변에 가득한 디지털 기기에는 거의 전부 훨씬 작은 시스템이 내장되어 있다.
- 이른바 사물 인터넷, 즉 네트워크에 연결된 온도 조절 장치, 보안 카메라, 스마트 조명, 음성 인식 장치를 포함한 수많은 기기도 프로세서를 기반으로 작동한다.
3) 슈퍼컴퓨터
- 과학 기술 연산을 비롯한 다양한 분야에 사용되는 고속 컴퓨터로, 보통 많은 수의 프로세서와 대량의 메모리를 사용한다.
- 사용되는 프로세서 자체도 종래 프로세서보다 특정 종류의 데이터를 훨씬 빨리 처리하는 명령어로 구성되어 있다.
- 요즘의 슈퍼컴퓨터는 전용 하드웨어를 사용하는 대신, 속도는 빨라도 기본적으로는 평범한 프로세서로 구성된 클러스터를 기반으로 구현된다.
클러스터 : 디스크로부터 데이터를 읽어오는 시간을 줄이기 위해서 조인이나 자주 사용되는 테이블의 데이터를 디스크의 같은 위치에 저장시키는 방법
1. 슈퍼컴퓨터 내부구조
2. 슈퍼컴퓨터 도입 감염병 예측
4) 플롭스
- 슈퍼컴퓨터의 속도는 플롭스, 즉 초당 수행할 수 있는 부동 소수점 연산 횟수로 측정된다.
- 부동 소수점 연산이란 소수 부분을 포함하는 수에 대한 산술 연산을 뜻한다.
5) GPU
- GPU는 범용 CPU보다 그래픽 관련 계산을 훨씬 빠르게 수행하는 그래픽 전용 프로세서다.
- GPU는 게임에 필요한 고속 그래픽 처리를 위해 개발되었고, 휴대전화용 음성 처리나 신호 처리에도 사용된다.
- 또한 GPU는 일반 프로세서가 특정한 종류의 작업을 빠르게 처리하는 데 도움을 준다.
- GPU는 간단한 산술 연산을 병렬로 대량 처리할 수 있다.
따라서 일부 계산 작업이 병렬 처리 가능한 연산을 포함하며, 이를 GPU로 넘겨 줄 수 있다면, 전체 계산이 훨씬 더 빨라진다. GPU는 특히 머신러닝에 유용하다. 머신러닝에서는 큰 데이터셋의 여러 부분에 같은 계산을 독립적으로 수행할 일이 많기 때문이다.
6) 분산 컴퓨팅
- 분산 컴퓨팅은 네트워크로 연결되어 서로 독립적으로 작동하는 여러 대의 컴퓨터를 일컫는 말이다.
- 분산 컴퓨팅 시스템은 메모리를 공유하지 않고 물리적으로 넓게 흩어져 있다.
- 컴퓨터가 흩어져 있을수록 통신이 잠재적 병목 현상을 일으킬 가능성이 커질 수도 있지만, 사람과 컴퓨터가 공간적으로 멀리 떨어져 있어도 상호 협력해서 일할 수 있다는 장점이 있다.
7) 컴퓨터
- 모든 컴퓨터는 동일한 핵심 원칙을 갖는다. 즉, 한없이 다양한 작업을 수행하도록 프로그래밍 될 수 있는 범용 프로세서에 기반을 둔다.
- 각 프로세서에는 산술 연산을 하고, 데이터 값을 비교하고, 기존 계산 결과에 기초하여 다음에 수행할 명령어를 선택하는 간단한 명령어로 이뤄진 한정된 레파토리가 있다.
- 전반적인 아키텍처는 1940년대 후반 이래로 크게 바뀌지 않았지만, 물리적인 구조는 놀랍도록 빠르게 진화를 거듭해 왔다.
- 모든 컴퓨터는 논리적인 면에서 같은 능력을 갖추고 있고, 속도와 메모리 요구사항 같은 현실적인 문제를 제외하면 정확히 똑같은 것을 계산할 수 있다.
- 이는 1930년대에 몇 명의 사람들이 독자적으로 증명해 냈는데, 영국의 수학자 앨런 튜링도 그중 하나다.
8) 튜링 머신
- 튜링의 접근 방식은 단순한 컴퓨터를 묘사하고 그 컴퓨터가 매우 상식적인 수준에서 계산 가능한 것이면 어떤 것이든 계산할 수 있다는 것을 증명했다.
9) 범용 튜링 머신
- 이어서 그는 다른 어떤 튜링 머신이라도 모방하여 작동할 수 있는 튜링 머신을 만드는 방법을 보여 주었다.
- 범용 튜링 머신인 것처럼 작동하는 프로그램을 작성하기는 쉽고, 실제 컴퓨터인 것처럼 작동하는 범용 튜링 머신용 프로그램을 작성하는 것도 가능하다.
이러한 이유로 모든 컴퓨터는 얼마나 빨리 계산할 수 있느냐에 대해서는 차등이 있더라도 무엇을 계산할 수 있느냐에 대해서는 서로 동등하다.
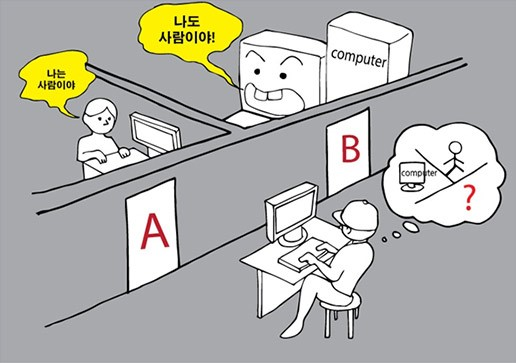
10) 튜링 테스트
- 1950년에 튜링은 <계산 기계와 지능>이라는 논문을 발표했다. 이 논문에서 그는 컴퓨터가 인간 수준의 지적 능력을 보여 줄 수 있는지를 평가하는데 사용할 테스트를 제안했다.
- 튜링은 질문자가 인간과 컴퓨터를 확실히 구분할 수 없다면 컴퓨터가 인간 수준의 지적 행동을 수행하는 것이라고 보았다.
- 컴퓨터는 이제 일부 영역에서는 인간 수준 혹은 그 이상으로 작동한다.
- 하지만 그렇다고 인간의 종합적인 지능을 모방하는 것은 확실히 아니다.
유진 구스트만
11) 캡차
- 캡차는 컴퓨터와 인간을 구별하기 위한 완전 자동화된 공개튜링 테스트의 약자이다.
- 캡차는 왜곡된 문자 패턴으로서 웹 사이트 사용자가 프로그램이 아니라 인간임을 확인할 용도로 폭넓게 사용된다.
- 캡차는 역 튜링 테스트의 한 사례인데, 일반적으로 사람이 컴퓨터보다 시각적인 패턴을 더 잘 식별할 수 있다는 점을 이용하여 인간과 컴퓨터를 구별하려는 시도이기 때문이다.
- 물론 캡차는 시각 장애가 있는 사용자는 풀 수가 없다.

27. 작문과 비슷한 프로그래밍
1) C언어
포트란, 코볼, 베이직이 성공했던 이유 중 하나는 특정 응용 분야에 집중했기 때문이다. 이 언어들은 굳이 모든 프로그래밍 과제를 처리하려고 하지 않았다. 1970년대에 '시스템 프로그래밍' 용도로, 즉 어셈블러, 컴파일러, 텍스트 편집기 같은 프로그래머 도구와 심지어 운영체제까지 작성할 목적으로 사용할 언어들이 만들어졌다. 그중 단연코 가장 성공적이었던 것은 C언어다. C는 1973년에 벨 연구소에서 일하던 데니스 리치가 개발했고 아직도 폭넓게 사용되며 가장 인기 있는 언어 중 하나다. C는 개발 이후 미미하게 변경돼서 오늘날의 C 프로그램은 30~40년 전의 코드와 거의 비슷해 보인다.
#include <stdio.h>
int main(){
int num, sum;
sum = 0;
while (scanf("%d", &num) != E0F && num != 0)
sum = sum +sum;
printf("%d/n", sum);
return 0;
}2) C++
1980년대에 들어서는 규모가 매우 큰 프로그램의 복잡성 관리를 도울 의도로 설계된 언어들이 개발되었고, C++가 대표적이다. C++는 비야네 스트롭스트룹이 개발했는데, 그 또한 벨 연구소에서 일했다. C++은 C에서 진화했고 C 프로그램은 대부분 C++프로그램에서도 유효하지만(예제) 그 반대는 그렇지 않다. 예제는 C++로 작성된 '수 합산하기' 프로그램 예제로, 이 방법 말고도 작성 코드는 다양하다.
#include <iostream>
using namespace std;
int main(){
int num, sum;
sum = 0;
while (cin >> num && num != 0)
sum = sum +sum;
count << sum << endi;
return 0;
}오늘날 컴퓨터에서 사용되는 주요 프로그램 대부분은 C나 C++로 작성됐다.
C, C++와 오브젝티브(C의 변종) - 맥 소프트웨어
C, C++ - 워드, 파이어폭스, 크롬, 엣지
C - 유닉스, 리눅스
1990년대에는 인터넷과 월드 와이드 웹의 성장에 대응하여 더 많은 언어가 개발됐다.
컴퓨터에는 계속해서 더 빠른 프로세서와 용량이 큰 메모리가 장착되었고, 프로그래밍을 빠르고 편하게 하는 것이 컴퓨터가 효율적으로 돌아가도록 하는 것보다 중요해졌다. 자바와 자바스크립트 같은 언어는 의도적으로 이러한 트레이드오프레 맞춰 설계됐다.
3) 자바
자바는 1990년대 초에 썬 마이크로시스템즈에서 일하던 제임스 고슬링이 개발했다.
원래 자바의 적용 대상은 속도는 그다지 중요하지 않지만 유연성이 중요한 가전 제품과 전자 기기 같은 작은 임베디드 시스템이었다. 이후 자바는 웹페이지상에서 실행할 용도로 변경되었지만 별로 인기를 얻지 못했고, 대신 웹 서버에 널리 사용되고 있다.
예를 들어 사용자가 이베이 같은 웹사이트를 방문하면 사용자의 컴퓨터 는 웹페이지를 표시하기 위해 C++와 자바스크립트를 실행하겠지만 , 이베이는 방문자의 브라우저로 전송할 페이지를 생성하는 데 자바를 사용할 가능성이 크다 . 자바는 안드로이드 앱을 작성하는 주요 언어이기도 하다 .
자바는 C++보다 단순하지만(비슷하게 복잡한 방향으로 진화하고 있기는 하다) C보다는 더 복잡하다 . 또한 C보다 더 안전하기는 한데 , 몇몇 위험한 특성을 제거했고 메모리에서 복잡한 자료 구조를 관리하는 일처럼 에러가 발생하기 쉬운 작업을 처리할 내장 메커니즘을 갖추고 있기 때문이다 . 그래서 프로그래밍 수업에서 처음 배우는 언어로도 인기가 높다.
예제는 자바로 작성된 ' 수 합산하기 ' 프로그램이다 . 이 프로그램은 다른 언어로 된 코드보다는 조금 긴데 , 자바의 특성상 그런 면이 있지만 몇 개의 계산을 합치면 2∼3줄 더 줄일 수 있다.
import java.util.*;
class Addup {
public static void main (String [] args) {
Scanner keyboard = new Scanner(System.in);
mnt num, sum;
sum = 0;
num = keyboard.nextlntO;
while (num != 0) {
sum = sum + num;
num = keyboard.nextlntO;
}
System. out. printl..n(sum) ,
}
}4) 프로그램과 프로그래밍
특정 작업을 하는 프로그램을 작성하는 데는 ' 항상 많은 방법이 있다는 것이다 . 이러한 의미에서 프로그래밍은 작문과 비슷하다 . 문체와 적절한 어휘 사용 등은 글을 쓸 때도 중요하지만 프로그램을 작성할 때도 중요하다 . 프로그램을 어떻게 작성했는지를 보고 훌륭 한 프로그래머인지 판단할 수도 있다 . 다른 사람이 작성한 코드 중에 자신에게 필요한 작업을 수행하는 코드를 어렵지 않게 찾을 수 있어서 , 다른 프로그램을 복사한 프로그램을 심심찮게 찾아볼 수 있다 .
5) 자바스크립트
자바스크립트는 C에서 시작된 광범위한 언어군에 속하지만 다른 언어 들과 차이점이 많다 .
자바스크립트는 1995년에 넷스케이프Netscape에서 근무하던 브렌던 아이크Brendan Eich가 만들었다 . 이름의 일부가 겹친다는 점 을 제외하면 자바스크립트는 자바와 아무 관계가 없다 . 자바스크립트는 처음부터 웹페이지의 동적인 효과를 구현하기 위해 브라우저 내부에서 사용할 목적으로 설계되었고 , 오늘날 거의 모든 웹페이지는 자바스크립트 코드를 어느 정도 포함하고 있다 .
(1) 시험 삼아 무언가 만들어 보기 쉽다 . 우선 언어 자체가 단순하다 .
(2) 컴파일러가 모든 브라우저에 내장되어 있어 별도로 다운 로드하지 않아도 된다 .
(3) 계산한 결과를 바로 볼 수 있다 .
예제에 몇 행을 추가한 다음 웹페이지에 올리면 전 세계 누구라도 이 프로그램을 볼 수 있다.
var num, sum;
sum = 0;
num = pronipt("Enter new value, or 0 to end");
while (num != '0') {sum = sum + parselnt(num);
num = prompt("Enter new value, or 0 to end");
}
alert(sum);
6) 파이썬
파이썬은 네덜란드 암스테르담의 C\Xllcentrum Wiskunde & Informatica , 네덜란드 국립 수학 정보과학연구소에서 일하던 귀도 반 로섬Guido van Rossum이 개발해서 1991 년에 처음 발표한 언어다 . 파이썬은 C, C++ , 자바 , 자바스크립트와 구문 규칙 면에서 약간 다른데 , 가장 눈에 띄는 부분은 문장을 그룹화하는 데 중괄호 대신 들여쓰기를 사용한다는 점 이다.
파이썬은 처음부터 가독성에 초점을 두고 설계되었다 . 파이썬은 배우기 쉽고 , 생각할 수 있는 거의 모든 프로그래밍 과제에 필요한 라이브러리를 풍부하게 제공해서 가장 널리 사용되는 언어 중 하나로 자리 잡았다 .
sum = 0
num = input()
while nun != '0':
sum = sum + int(num)
num = input()
print(sum)프로그래밍 언어는 짐작건대 우리는 더 많은 컴퓨터 자원을 우리에게 유용한 방향으로 사용함으로써 프로그래밍을 계속 해서 쉽게 만들 것이다 . 또한 프로그래머가 더 안전하게 사용할 수 있는 언어를 만드는 방향으로 나아갈 것이다 . 예를 들어 , C 언어는 매우 예리한 도구다 . C 언어로는 늦게까지 검출되지 않는 프로그래밍 에러를 무심코 만들기 쉬운데 , 이런 에러는 어쩌면 이미 흉악한 목적으로 이용된 다음에야 발견될 수도 있다 . C 이후에 나온 언어들은 이러한 에러를 일부 방지하거나 검출하기 쉽게 되어 있지만 , 더 느리게 실행되거나 메모리를 더 많이 차지 하는 등의 희생이 따른다 . 대체로는 이런 방향으로 나아가는 것이 정당한 트레이드오프지만 , 자원을 덜 쓰면서 빠른 코드를 작성하는 것이 매우 중요해서 C처럼 효율성이 높은 언어가 계속 사용될 응용 분야가 분명히 아직 많다 .
예를들면 자동차 , 항공기 , 우주선 , 무기 등에 있는제어 시스템이 그렇다. 각 언어가 튜링 머신을 모방하여 작동하거나 , 튜링 머신이 각 언어를 모방하여 작동하는 데 사용될 수 있다는 점에서 모든 프로그래밍 언어는 형식상 동등한 관계에 있다 . ' 그러나 모든 언어는 절대 모든 프로그래밍 작업에 대해 똑같이 효율적이지는 않다 . 복잡한 웹페이지를 제어하는 자바 스크립트 프로그램을 작성하는 일과 자바스크립트 컴파일러를 구현하는 C++ 프로그램을 작성하는 일 사이에는 막대한 차이가 있다 .
각 언어는 효율성, 표현력, 안전성, 복잡성 같은 문제 간 트레이드오프 를 고려해서 만들어진 결과다 . 많은 언어는 분명히 기존 언어가 가진 약점 을 인식하면서 그에 대한 반작용으로 나타나고 , 기존 언어에서 배운 교훈 과 더 좋아진 컴퓨팅 성능을 반영하며 , 설계자의 개인적인 취향에 크게 영향을 받는다 . 새로운 응용 분야가 생기면 새로운 영역에 주안점을 둔 새 언어가 만들어지기도 한다.
참고자료
https://www.tiobe.com/tiobe-index/
https://www.youtube.com/watch?v=p_v_js0mxVc
36. 파일 시스템과 블록
(1) 파일 시스템
운영체제에서 하드 디스크 , CD와 DVD , 다른 이동식 메모리 장치 같은 물리적인 저장 매체를 파일과 폴더의 계층 구조처럼 보이게 하는 부분
논리적 구성과 물리적 구현 간의 분리를 보여주는 훌륭한 사례다 .
파일 시스템은 다양한 종류의 장치에 정보를 조직화하고 저장하지만 , 운영체제는 모두 동일한 인터페이스로 표시한다 .
파일 시스템이 정보를 저장하는 방식은 실생활에 영향을 미칠 뿐더러 법적인 영향력도 가진다 .
따라서 파일 시스템에 대해 배우는 것은 '파일 제거하기' 가 왜 해당 내용이 영원히 사라졌음을 의미하지 않는지 이해하기 위해서이기도 하다.
대부분은 윈도우 파일 탐색기나 맥Os 파인더를 사용해 봤을 것 이다 .
각 프로그램에서는 최상위(예를 들면 , 윈도우의 C: 드라이브)부터 시작하는 계층 구조를 보여 준다 .
폴더는 다른 폴더와 파일의 이름을 담고 있다 . 폴더를 탐색해보면 더 많은 폴더와 파일이 나타난다.
(유닉스 계열 운영체제에서는 전통적으로 폴더 대신 디렉터리directory라는 용어를 사용 한다.)
폴더는 조직화된 구조를 제공하는 반면 , 파일은 문서 , 사진 , 음악, 스프레드시트 , 웹페이지 등의 실질적인 내용을 담고 있다 . 컴퓨터가 보유 하는 모든 정보는 파일 시스템 에 저장되고 , 사용자는 파일 시스템을 통해 정보에 접근한다 .
파인더와 파일 탐색기는 파일이 어디 있는지 이미 알 때 가장 유용하다 . 언제든지 파일 시스템 계층 구조의 루트 , 즉 최상위에서부터 탐색해 볼 수 있다 . 파일이 어디 있는지 모른다면 맥Os의 스포트라이트Spottight 같은 검색 도구를 사용해야 한다.
파일 시스템은 이 모든 정보를 관리하면서 애플리케이션이나 운영체제 의 나머지 부분이 정보를 읽고 쓸 수 있도록 접근 가능하게 만든다 . 또한 파일에 대한 접근이 효율적으로 수행 되고 서로 간섭하지 않도록 조정하는 역할을 하고 , 데이터의 물리적인 위치를 계속 파악한다.
각각의 데이터 조각을 반드시 서로 분리해 알 수 없는 이유로 이메일의 일부가 스프레드시트나 납세 신고서에서 발견되지 않도록 한다 . 다수의 사용자를 지원하는 시스템 에서는 프라이버시와 보안을 강하게 적용해서 한 사용자가 다른 사용자의 파일에 권한 없이 접근할 수 없게 하며 , 사용자마다 사용할 수 있 는 공간의 용량에 한도를 부과할 수 있다.
파일 시스템 서비스는 가장 낮은 레벨의 시스템 콜을 통해 사용할 수 있 으며 , 파일 시스템 서비스를 만들 때 공통적인 부분은 라이브러리에 제공 되어 있어 프로그래밍하기 쉽다.
(2)보조 기억 장치 파일 시스템
파일 시스템은 매우 다양한 물리적 시스템이 균일한 논리적 구조로 나타나게 하는 방법을 보여 주는 훌륭한 사례다 .
파일 시스템은 한 파일이 사용하는 바이트를 다른 파일이 사용하는 바이트와 같은 블록에 저장하지 않는다 .
그러므로 마지막 블록이 완전히 꽉 차지 않는다면 약간의 공간이 낭비된다 .
이 모든 정보를 파일 탐색기나 파인더 같은 프로그램에서 확인할 수 있다.
폴더 엔트리는 또한 그 파일이 드라이브 어디에 저장되어 있는지 , 즉 5 억 개의 블록 중 어느 것이 파일의 바이트를 담고 있는지 정보를 넣고 있 다 .
(3)파일의 위치 정보를 관리하는 방법
폴더 엔트리가 블록 번호 목록을 담고 있거나 ,
블록 번호 목록을 담고 있는 블록을 참조하기도 하고 ,
또는 첫 번째 블록 번호를 담고 있어서 차례로 두 번째 블록 번호, 다음 블록 번호를 계속해서 구하는 방법도 있다.
블록 목록을 참조하는 블록들의 구조를 개략적으로 보여 주며 , 종래의 하드 드라이브에서 찾아볼 수 있는 형태다 . 같은 파일을 나눠 담고 있는 블록들이 하드 드라이브에서 물리적으로 인접해 있지 않아도 된다 . 적어도 용량이 큰 파일에서는 블록들이 실제로 인접해 있지 않을 공산이 크다 .
1MB 파일이라면 1,000개의 블록을 차지하며 블록들은 어느 정도 흩어져 있다 . 폴더와 블록 목록 자체는 같은 드라이브상의 블록에 저장된다.

(4) SSD
SSD는 물리적 구현은 크게 다르겠지만 하드 드라이버와 기본 아이디어 는 같다 . 앞서 언급했듯이 요즘은 대부분의 컴퓨터에서 SSD를 애용한다. 바이트당 가격이 비싸기는 해도 더 작고 훨찐 안정적이고 가벼우며 전력 소모가 적기 때문이다 . 사실 파인더나 파일 탐색기 같은 프로그램에서 보면 차이가 전혀 없다 .
하지만 SSD 장치는 하드 드라이브와는 다른 드라이버를 사용하며 , 장치 자체에 정보가 어느 위치에 있는지 기억하기 위한 정교한 코드가 들어 있다 . 이는 SSD 장치의 각 영역이 사용될 수 있는 횟수에 제한이 있기 때문이다 .
(5) 웨어 레벨링
SSD 내부 소프트웨어는 각 물리적 블록이 몇 번 사용되었는지 파악하고 , 각 블록이 거의 같은 횟수로 사용되도록 데이터 를 옮긴다 .
폴더는 다른 폴더와 파일이 어디에 있는지 정보를 담고 있는 파일이다 . 파일 내용과 구조에 대한 정보가 정확해야 하고 완벽하게 일치해야 하므로 파일 시스템은 폴더의 내용을 관리하고 유지하기 위한 권리를 독점적으로 보유한다 .
사용자와 애플리케이션은 파일 시스템에 요청을 해야만 간접적으로 폴더 내용을 바꿀 수 있다. 어떤 관점에서는 폴더 또한 파일이다 . 파일 시스템이 폴더 내용에 완전히 책임을 지고 있고 , 애플리케이션이 그 내용을 직접 바꿀 방법이 없다는 점을 제외하면 폴더와 파일이 저장되는 방법에는 차이가 없다 . 하지만 가장 낮은 레벨에서 보면 폴더는 그저 블록이며 , 모두 같은 메커니즘으로 관리된다.
프로그램이 기존 파일에 접근하려 할 때 , 파일 시스템은 계층 구조의 최상위부터 시작해서 파일 경로명의 각 요소를 해당하는 폴더 에서 찾으면서 파일을 검색해야 한다 .
예를 들어 , 맥 컴퓨터에서 찾으려는 파일 경로가 /Users/bwk/book/book.txt라면 파일 시스템은 파일 시스템의 최상위에서 Users를 찾고 , 다음으로 그 폴더에서 bwk를 찾고 , 다음으로 그 폴더에서 book을 , 이어서 그 폴더에서 book. txt를 찾을 것이다 . 윈도우에서는 파일 이름이 C:\My Documents\book\book.txt 같은 꼴이 될 수 있고 , 검색 과정 은 비슷하다.
이 방식은 효율적인 전략인데 , 경로에서 폴더를 찾아 들어갈 때마다 그 폴더 이하에 있는 파일과 폴더에 수행되는 검색의 범위가 좁아지기 때문이다 . 해당되지 않는 파일과 폴더는 검색 대상에서 제외된다 . 여러 파일이 경로의 일부를 공유할 수는 있지만 전체 경로명이 유일무이해야 한다는 조건을 반드시 충족해야 한다 . 실제로는 프로그램과 운영체제가 현재 사용되는 폴더를 계속 파악하기 때문에 검색이 매번 최상위에서 시작할 필요는 없다 . 또한 시스템이 작업 속도를 높이기 위해 자주 사용되는 폴더를 캐싱하기도 한다. 프로그램이 새 파일을 생성하려고 할 때 , 파일 시스템에 요청을 한다.
파일시스템 과정
1. 적절한 폴더에 새로운 엔트리를 넣으면서 이름 , 날짜 등을 넣고 , 크기를 0으로(완전히 새로운 파일에는 아직 어떤 블록도 할당되지 않았으므로) 표시한다 .
2. 나중에 프로그램이 파일에 데이터를 쓰면(가령 메일 메시지에 텍스트를 추가하면)
3. 요청된 정보를 담기에 충분한 수의 미사용 블록free block을 찾아서 데이터를 복사해 넣고 , 폴더의 블록 목록에 그 블록들을 삽입하고 , 애플리케이션으로 되돌아간다.
이 점은 파일 시스템이 드라이브상에서 현재 사용되지 않는 , 즉 어떤 파일의 일부가 아닌 모든 블록의 목록을 유지하고 있다는 것을 암시한다 . 새로운 블록에 대한 요청이 도착하면 미사용 블록의 목록에서 가져온 블록으로 요청을 만족시킨다 . 파일 시스템에서 관리하는 미사용 블록 목록에는 운영체제만 접근할 수 있고 애플리케이션은 접근할 수 없다.
37. 파일을 휴지통에 넣을 때 일어나는 일
파일이 윈도우나 맥Os에서 제거되면 ' 휴지통'으로 간다 . 휴지통은 일부 속성이 조금 다르다는 점을 제외하면 그저 또 다른 폴더처럼 보인다 . 사실 휴지통이 바로 그런 것이다 . 파일이 제거되기로 하면 그 파일의 폴더 엔트리와 전체 이름이 현재 폴더에서 휴지통이라는 폴더로 복사되고 원래 폴더 엔트리는 지워진다 . 파일의 블록과 그 내용은 전혀 바뀌지 않는다 . 휴지통에서 파일을 복원할 때는 이 과정을 정반대로 수행해서 , 엔트리를 원래 폴더로 복구한다. ' 휴지통 비우기 ' 가 원래 의도했던 제거 작업에 더 가깝다 .
이 작업을 요청하면 휴지통에 있는 폴더 엔트리가 지워지고 블록은 미사용 목록에 진짜로 추가된다 . 이 절차는 휴지통 비우기가 명시적인 요청에 의해 수행되든 , 파일 시스템 이 빈 공간이 부족하다는 것을 알고 사용자가 모르는 상태 에서 조용히 진행 되든 마찬가지로 적용된다.
' 휴지통 비우기 ' 를 클릭해서 명시적으로 휴지통을 비운다고 가정해 보 자 . 그렇게 하면 휴지통 폴더 자체에 있는 폴더 엔트리는 삭제되고 해당 블록이 미사용 목록에 들어가지만 , 그 내용은 아직 삭제되지 않은 상태다. 원래 파일에 할당된 각 블록의 모든 바이트는 아직 그대로 있다 . 그 블록 이 미사용 목록에서 꺼내쳐서 새로운 파일에 할당되기 전까지는 새로운 내용으로 덮어 쓰이지 않는다.

이렇게 삭제가 바로 일어나지 않는다는 것은 제거했다고 생각한 정보가 아직 존재하고 , 누군가 그 정보를 찾을 방법을 안다면 손쉽게 접근할 수 있음을 뜻한다 . 물리적 블록 단위로 드라이브를 읽는 프로그램, 즉 파일 시스템 계층 구조를 통하지 않고 디스크를 읽는 프로그램이라면 예전 내용을 확인할 수 있다 . 2020년 중반에 마이크로소프트가 발표한 윈도우 파일 복구Windows File Recovery라는 무료 툴은 정확히 이러한 방식으로 수많은 파일 시스템과 저장 매체에 파일 복구를 수행한다.
여기에는 잠재적인 이점이 있다 . 디스크에 뭔가 이상이 생겨 파일 시스템이 엉망이 되었을 때도 아직 정보를 복원할 수 있을지 모른다 . 하지만 파일을 제거해도 데이터가 완전히 사라졌다는 보장이 없는 점은 데이터에 사적인 내용이 있거나 여러분이 뭔가 나쁜 일을 꾸미고 있어 진짜로 정보가 제거되기를 바란다면 좋지 않은 일이다 .
더 좋은 방법은 하드 디스크를 강한 자석 근처에 놓아 자성을 없애 버리는 것이다 . 최선의 방법은 물리적으로 파괴하는 것이며 , 저장한 정보를 확실히 사라지게 하는 유일한 방법 이다.

하지만 이마저 충분하지 않을 수 있다 . 만일 데이터가 항상 자동으로 백업되고 있거나 자신의 드라이브 대신 네트워크 파일 시스템이나 ' 클라우드 ' 어디엔가에 파일이 보관되고 있다면 말이다. 폴더 엔트리 자체에도 어느 정도 비슷한 상황이 적용된다 . 파일을 제거 할 때 파일 시스템은 폴더 엔트리가 더 이상 유효한 파일을 가리키지 않는다는 점에 주목할 것이다 .
파일 시스템이 폴더에 ' 이 엔트리는 사용 중이지 않습니다'를 뜻하는 비트를 설정해서 그렇게 할 수 있다 . 이후 폴더 엔트리 자체가 재사용되기 전까지는 재할당되지 않은 모든 블록의 내용을 포함해 파일에 대한 원래 정보를 복원하는 것이 가능하다 . 이 메커니즘은 1980년대에 마이크로소프트의 MS-DOS 시스템에 사용된 상용 파일 복원 프로그램의 핵심 원리로 , 파일 이름의 첫 번째 문자를 특별한 값으로 설정 함으로써 미사용 항목을 표시했다 . 이 방식 덕분에 파일이 제거되고 얼마 지나지 않아 복원 시도가 이루어지면 전체 파일을 쉽게 복원할 수 있었다.
파일을 만든 사람이 파일이 삭제됐다고 생각한 후에도 한참 동안 그 내용이 남아 있을 수 있다는 사실은 디스커버리 제도 나 문서 보존 같은 법적 절차에 대한 시사점을 제공한다 .대부분의 정보가 그곳에 저장되며 컴퓨터에서 가장 자주 볼 수 있는 장치이다 .
파일 시스템의 추상화
하지만 파일 시스템의 추상화는 다른 저장 매체에도 적용된다. CD-ROM과 DVD도 마찬가지로 폴더와 파일 계층 구조로 되어 있는 파일 시스템처럼 정보에 접근하게 한다 . USB 드라이브와 SD 카드의 플래시 메모리 파일 시스템은 매우 흔히 사용된다 . 이들 저장 매체를 윈도우 컴퓨터에 연결하면 또 다른 디스크 드라이브로 나타난다 . 저장된 내용을 파일 탐색기로 탐색할 수 있고 , 내장 드라이브와 똑같이 파일 을 읽고 쓸 수 있다 . 유일한 차이는 용량이 더 작고 접근 속도가 다소 느릴 수 있다는 점 이다.
소프트웨어는 물리적인 장치가 파일 시스템처럼 보이게 하며 , 다양한 운영체제에 서도 동일하게 추상화된 폴더와 파일 구조로 나타나게 한다 . 내부적인 구성 방식은 널리 사용되는 ' 사실상의 ' 표준인 마이크로소프트 FATFile Allocation Table 파일 시스템일 가능성이 높지만 , 경우에 따라 다르므로 확실히는 알 수 없고 알 필요도 없다 . 추상화는 완벽하기 때문이다 .
하드웨어 인터페이스와 소프트웨어 구조의 표준화 덕분에 이러한 추상화가 가능하다.
어설프고 독자적인 소프트웨어와 하드웨어 대신에 표준화된 매쳬를 이용해 친숙하고 균일한 인터페이스를 사용할 수 있게 됐다 . 제조사도 더 이상 전용 파일 전송 소프트웨어를 제공하지 않아도 돼서 편할 것이다.
네트워크상의 다른 컴퓨터에 있는 파일 시스템은 사용 중인 로컬 컴퓨터와 같은 종류일 수도 있고(예컨대 둘 다 윈도우 컴퓨터) 다른 종류일 수도 있다(맥Os나 리눅스) . 플래시 메모리 기반 장치와 마찬 가지로 , 소프트웨어가 차이점은 숨기고 균일한 인터페이스를 제공함으로 써 파일 구조가 로컬 컴퓨터 에 있는 일반 파일 시스템처럼 보이게 한다 .
네트워크 파일 시스템은 주된 파일 저장소로도 사용되지만 백업 용도로 도 자주 쓰인다 . 파일의 이전 버전 여러 개를 서로 다른 위치에 있는 보관용 저장 매체로 복사해 둔다 . 이렇게 하면 랜섬웨어 공격이나 중대한 기록 의 원본을 훼손할 우려가 있는 화재 같은 재난에서 데이터를 지킬 수 있다 . 어떤 디스크 시스템은 또한 RAiDRedundantArray of Independent Disks , 복수 배열독 립 디스크 기법을 활용한다 . 이 기술은 디스크 중 하나가 고장 나더라도 정보 를 복원할 수 있게 하는 오류 수정 알고리즘을 이용하여 여러 개의 디스크 에 데이터를 기록한다 . 물론 이러한 시스템은 정보의 모든 흔적을 확실히 지우기 어렵게 만드는 요인이 되기도 한다.
참고자료
https://www.youtube.com/watch?v=0wfOO2DEGZ0&t=264s
63. 표준과 프로토콜의 세계, 인터넷
인터넷
인터넷은 느슨하고 쳬계가 없으며 혼란스럽고 임시적인 네트워크 모음
네트워크와 그 위에 있는 컴퓨터가 서로 통신하는 방법을 구정하는 표준으로 묶여 있다.
물리적 특성이 서로 다르고(광섬유 , 이더넷 , 무선 등) 서로 멀리 떨어져 있기도 한 네트워크를 어떻게 연결할까?
우선 네트워크와 컴퓨터를 식별 하기 위해서 이름과 주소가 필요한데 , 전화번호부로 이름과 전화번호를 찾는 것과 유사하다 . 다음으로 , 직접 연결되지 않은 네트워크 사이의 경로 를 찾을 수 있어야 한다 . 정보가 이동함에 따라 그 형식을 어떻게 바꿀 것 인지 , 또한 오류 , 지연 , 과부하에 대처하는 방법 등 여러 가지 다소 불분명 한 문제에 대해서도 합의가 필요하다 . 이러한 합의 없이는 통신이 어려워 지거나 불가능해질 수도 있다.
프로토콜protocoL
모든 네트워크에서 , 특히 인터넷에서 오는 데이터를 어떤 형식으로 구성할지 , 누가 먼저 말할 것이고 어떤 응답이 이어질 수 있는지 , 오류를 어떻게 처리할지 등에 대한 합의는 프로토콜protocoL로 처리된다.
프로토콜은 일반적인 대화에서 이루어지는 약속과 어느 정도 비슷하다 . 즉 , 상대방과 소통하기 위한 일련의 규칙이다 .
하지만 네트워크 프로토콜은 사회적 관습이 아닌 기술적 고려 사항에 바탕을 두며 , 사회 조직에 적용되는 가장 엄격한 규칙보다도 훨씬 더 엄밀하게 정의된다 . 잘 이해되지 않을 수도 있지만 , 인터넷에서는 그런 규칙이 반드시 필요 하다 .
정보를 형식화하는 방법 , 컴퓨터 간에 정보를 교환하는 방법 , 컴퓨터를 식별하고 인가(접근 권한을 부여)하는 방법 , 무언가 실패했을 때 해 야 할 일 등에 대한 프로토콜과 표준에 모두 동의해야 한다.
프로토콜과 표준에 합의하는 일은 복잡할 수 있는데 , 많은 기득권 세력이 존재하기 때문이다 .
여기에는 장비를 만들거나 서비스를 판매하는 회사 , 특허나 영업 비밀을 보유한 단체 , 국경을 넘어 전송되거나 시민들 간에 전달되는 정보 를 감시하고 통제하고자 하는 정부까지 포함된다.
무선 서비스 스펙트럼처럼 일부 자원은 공급이 부족하다 .
웹사이트의 이름도 무정부 상태로는 관리할 수 없다 .
그런 자원은 누가 어떤 기준으로 할당할까?
한정된 자원을 사용하기 위해 누가 누구에게 무엇을 지불할까?
불가피하게 분챙이 발생하면 누가 판결을 내릴까?
분챙을 해결하는 데 어 떤 법쳬계가 적용될까?
과연 누가 규칙을 만드는 것일까?
규칙은 정부 , 기업 , 산업 협회 , 또는 유엔의 ITU 같은 명목상 객관적이거나 중립적인 기구가 만들겠지만 , 결국 규칙을 준수하는 데 모든 이들의 동의가 필요하다. 이러한 문제가 해결될 여지가 있음은 분명하다 .
선례가 될 수 있는 전화 시스템을 보면 , 결국 다양한 국가의 서로 다른 장비를 연결하면서도 전 세계적으로 잘 작동하고 있다 . 인터넷은 더 새롭고 규모가 크고 , 훨씬 더 무 질서하고 , 더 빠르게 변하기는 해도 거의 비슷하다 .
인터넷은 대부분 정부 독점이거나 엄격히 규제된 회사에 의해 운영되었던 전통적인 전화 시스템 의 통제된 환경에 비하면 무질서 상태에 가깝다 . 그러나 정치적 , 상업적 압력 때문에 인터넷은 초창기보다 덜 자유분방해졌고 구속은 더 심해쳤다.
64. 인터넷이 가능한 메커니즘
인터넷의 시작
인터넷은 1960년대에 지리적으로 멀리 떨어진 위치에 있는 컴퓨터를 연결하는 네트워크를 구축하려는 시도에서 시작됐다 . 프로젝트의 자금을 대부분 미국 국방성의 고등연구계획국Advanced Research Projects Agency, ARPA에서 지원받았 고, 이렇게 만들어진 네트워크는 아파넷ARPANET이라고 불리게 됐다 .
첫 번 째 아파넷 메시지는 1969년 10월 29일에 UCLA에 있는 컴퓨터에서 약 550km 떨어진 스탠퍼드 연구소에 있는 컴퓨터로 전송되었다 . 따라서 이 날이 인터넷이 탄생한 날이라고 할 수 있다(초기 실패 원인이 된 버그는 신속하게 해결되었고 다음 전송 시도는 성공했다).
처음부터 아파넷은 네트워크 구성 요소 중 하나에 이상이 생기더라도 견고하게 작동하고 , 문제가 발생한 부분을 우회해서 트래픽을 라우팅(경로 지정)하도록 설계됐다 . 최초의 아파넷 컴퓨터와 기술은 시간이 흐르면 서 더 새로운 컴퓨터와 기술로 교체됐다 . 원래 아파넷 자쳬는 대학교 컴퓨터과학부와 연구 기관을 연결할 목적이었지만 , 이후 1990년대에 상업적 영역으로 퍼져 나갔고 언젠가부터 ' 인터넷 ' 이라 부르게 됐다.
게이트 웨이와 라우터
오늘날 인터넷은 느슨하게 연결된 수백만 개의 독립적인 네트워크로 구성되어 있다 . 가까이 있는 컴퓨터끼리는 근거리 통신망으로 연결되는데, 주로 무선 이더넷이 사용된다 . 다음으로 이 근거리 네트워크들이 게이트 웨이gateway 또는 라우터router를 통해 다른 네트워크에 연결되는데,
한 네트워크에서 다음 네트워크로 정보 패킷을 라우팅하는데 전문화된 컴퓨터를 말한다(위키피디아에 따르면 게이트웨이는 더 일반척인 장치이며 라우터는 특수한 장치라고 하는데 , 이러한 용어 구분이 보편적인 것은 아니다) .
게이트웨이는 라우팅 정보를 서로 교환하여 국지 적으로라도 어떤 개체들이 연결되어 있고 접근 가능한지 파악할 수 있다.
각 네트워크는 집 , 사무실 , 기숙사에 있는 컴퓨터나 전화 등 여러 호스트 시스템을 연결할 수 있다 . 가정 내 개별 컴퓨터는 주로 무선 통신으로 라우터에 연결되고 , 라우터는 케이블이나 DSL로 ISPinternet Service Provider , 인터넷서비스제공업체에 연결된다 . 반면 사무실에 있는 컴퓨터는 유선 이더넷 연결을 사용하기도 한다. 앞에서 정보는 패킷이라는 덩어리로 네트워크를 통해 이동한다고 했다.
패킷
패킷은 형식이 지정된 일련의 바이트다 . 다양한 장치는 서로 다른 패킷 형식을 사용한다 . 패킷의 일부에는 패킷이 어디서 오고 어디로 향하는지를 알려 주는 주소 정보가 들어 있다 . 다른 부분에는 패킷의 길이 같은 패킷 자쳬에 대한 정보가 들어 있고 , 마지막으로는 패킷이 전달하는 정보인 페이로드 payLoad가 있다.
인터넷에서 데이터는 IP 패킷 packet으로 전달된다 . IP 패킷은 모두 같은 형식이다 .
어떤 네트워크에서든 IP 패킷은 하나 이상의 물리적 패킷에 실려 전송된다 .
큰 IP 패킷은 여러 개의 작은 이더넷 패킷으로 분할되는 데 , 최대 크기의 이더넷 패킷(약 1,500바이트)이 최대 크기의 IP패킷 (65,000바이트를 조금 넘는다)보다 훨씬 작기 때문이다 .
각 IP 패킷은 여러 개의 게이트웨이를 통과한다 .
각 게이트웨이는 최종 목적지에 더 가까이 있는 게이트웨이로 패킷을 보낸다 .
패킷이 여기저기 로 이동하면서 20개 정도의 게이트웨이를 통과하는데 , 이 게이트웨이들은 여남은 개의 회사나 기관이 각기 소유하고 운영하고 있어 서로 다른 국가에 있을 확률이 높다 .
트래픽은 최단 경로를 따를 필요가 없다 .
편의성과 비용 때문에 더 긴 경로로 패킷을 라우팅하기도 한다 .
출발지와 목적지가 미국 이외의 지역인 많은 패킷이 미국을 통과하는 케이블을 사용한다 .
이 점을 이용하여 NSA가 전 세계의 트래픽을 기록한 것이다.
여기까지 설명한 내용이 실제로 작동하는 데는 몇 가지 메커니즘이 필 요하다.
주소address
첫 번째는 주소address다 . 각 호스트 컴퓨터에는 전화번호처럼 인터넷상 의 모든 호스트 중에서 자신을 고유하게 식별할 주소가 있어야 한다 . 이 식별 번호인 IP 주소는 32비트(4바이트) 또는 128비트(16바이트) 이며 , 짧은 주소는 인터넷 프로토콜 버전 4(IPv4)이고 긴 주소는 버전 6(IPv6)이다 . IPv4는 오랫동안 사용됐고 여전히 지배적이지만 , 이제 사용 할 수 있는 IPv4 주소가 거의 소진되었으므로 1Pv6로의 전환이 가속화되고 있다.
IP 주소는 이더넷 주소와 비슷하다 . IPv4 주소는 관습적으로 4바이트 값의 각 바이트를 십진수로 나타내고 마침표로 구분해서 표기한다 . 140 .180. 223.42(www.princeton.edu의 주소) 같은 식이다 . 이 특이한 표기법은 점으로 구분된 십진수dotted decimat라고 하며 , 순수한 십진수나 십육진수보 다 사람들이 기억하기 쉽기 때문에 사용된다 . IPv6 주소는 관습적으로 16개의 십육진수 바이트를 두 개씩 콜론으로 구분해서 작성하며 , 예를 들면 2620:0: 1003: lOOc: 9227: e4ff : f ee9 : 05ec처럼 표시한다.
이 표기법은 점으로 구분된 십진수보다 덜 직관적이므로 여기서는 IPv4 를 예로 사용하겠다 . 맥Os의 시스템 환경설정이나 윈도우의 설정에서 IP 주소를 확인할 수 있고 , 휴대전화에서는 와이파이를 사용한다면 설정 메뉴에서 IP 주소를 알아낼 수 있다.
중앙에서 주소를 관리하는 기관은 연속적인 IP 주소 블록을 네트워크 관리자에게 할당하고 , 네트워크 관리자는 네트워크상의 호스트 컴퓨터에 개별 주소를 할당한다 . 따라서 각 호스트 컴퓨터는 자신이 속한 네트워크에 따라 로컬로 할당된 고유한 주소를 갖는다 .
이 주소는 데스크톱 컴퓨터 에서는 영구적이지만 , 모바일 장치에서는 동적이며 장치가 인터넷에 다시 연결될 때마다 바뀐다.
도메인 네임domain name
그다음은 이름name이다 . 사람들이 직접 접근하려고 시도하는 호스트는 사람이 사용하기에 적합한 이름을 가져야 한다 . 임의의 32비트 숫자를 기억할 수 있는 사람은 거의 없고 , 점으로 구분된 십진수 형태라도 마찬가지 이기 때문이다 . 이름은 www.nyu.edu 또는 ibm.com처럼 어디서나 찾아볼 수 있는 형식이며 , 이를 도메인 네임domain name이라고 한다 .
인터넷 인프라에서 필수적인 부분인 도메인 네임 시스템Domain Name System , 즉 DNS는 이름과 ip 주소 간 변환을 수행한다.
라우팅routing
세 번째는 라우팅routing 즉 , 각 패킷이 출발지에서 목적지까지의 경로를 찾는 메커니즘이 있어야 한다 . 앞서 언급한 게이트웨이가 이 메커니즘을 제공한다 . 게이트웨이는 어떤 개체가 어디에 연결되어 있는지 자기들끼리 라우팅 정보를 끊임없이 교환하고 , 그 정보를 이용하여 각 수신 패킷을 최종 목적지에 더 가까운 게이트웨이 쪽으로 계속 전달한다.
프로토콜protocol
마지막으로 , 프로토콜protocol이라는 , 정보가 한 컴퓨터에서 다른 컴퓨터 로 성공적으로 복사되도록 이상의 구성 요소와 나머지 구성 요소 모두가 어떻게 상호 운용되는지 정확하고 자세하게 설명하는 규칙과 절차가 있어 야 한다.
IP internet Protocol
IP internet Protocol라고 하는 핵심 프로토콜은 전송 중인 정보에 대해 균일 한 전송 메커니즘과 공통 형식을 정의한다 . IP 패킷은 자체 프로토콜을 사용하는 다양한 종류의 네트워크 하드웨어 에 의해 전달된다.
TCP Transmission Control Protoc
IP 바로 위에서는 TCP Transmission Control Protoc이 , 전송 제어 프로토콜라는 프로토콜이 TCP를 사용하여 출발지에서 목적지까지 임의 길이의 바이트 시퀀스를 전송하기 위한 안정적인 메커니즘을 제공한다. TCP 바로 위 에서는 상위 레벨 프로토콜들이 TCP를 사용하여 웹 브라우 징 , 메일 , 파일 공유 등 우리가 ' 인터넷 ' 이라고 생각하는 서비스를 제공한다 . 다른 프로토콜도 많이 있다 . 예를 들어 , IP 주소를 동적으로 변경하는 것은 DHCP(Dynamic Host Configuration Protoc)이 , 동적 호스트 구성 프로토콜라는 프로토콜에 의해 처리된다 . 이 모든프로토콜이 합쳐져서 인터넷을 규정한다
'프론트엔드 > CS' 카테고리의 다른 글
| HTTP와 HTTPS의 차이점 (0) | 2022.09.14 |
|---|---|
| API와 REST API (0) | 2022.09.13 |
| 브라우저 저장소(쿠키, 웹스토리지, 로컬스토리지, 세션스토리지) (0) | 2022.09.09 |
| DNS 원리 (0) | 2022.08.31 |
| 웹 브라우저가 하는 일 : 렌더링 6단계 (0) | 2022.08.25 |
- Total
- Today
- Yesterday
- redux middleware
- 동적(dynamic) 언어
- null
- find
- undefined
- 타입변환
- 참조형 데이터
- redux-thunk
- 얕은복사
- redux-middleware
- 기본형 데이터
- some
- redux
- foreach
- map
- 불변 객체
- redux thunk
- filter
- 비교 연산자
- findindex
- 느슨한 타입(loosely typed)
- EVERY
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |